

Na Grammarly, é essential que nossas diversas equipes de pesquisadores, linguistas e engenheiros de ML tenham acesso confiável aos recursos computacionais de que precisam, sempre que precisarem.
As responsabilidades de cada equipe são muito diferentes, assim como os requisitos de infraestrutura necessários para atingir seus objetivos:
- Lingüistas analíticos e computacionais: foco na amostragem de dados, pré-processamento e pós-processamento, anotação de dados e engenharia imediata
- Pesquisadores: trabalhar no treinamento e avaliação de modelos com base em dados e artigos de pesquisa de ponta
- Engenheiros de ML: implantar modelos prontos para produção em serviços de inferência, aplicando técnicas de otimização para encontrar o melhor equilíbrio entre desempenho e custo
Nosso sistema legado atendia a todas essas necessidades, mas começou a ter dificuldades para acompanhar a crescente demanda. Isso nos motivou a iniciar um projeto para reinventar nossa infraestrutura de ML na Grammarly. Neste artigo, descreveremos nossa trajetória e os desafios que enfrentamos ao longo do caminho.
Design e limitações do sistema legado
Nosso sistema legado de infraestrutura de ML tinha um design simples e nos serviu bem por quase sete anos.
O sistema compreendia uma interface net simples que fornecia uma interface interativa para criar instâncias EC2 de um determinado tipo e executar scripts bash predefinidos para instalar o software program necessário, dependendo do caso de uso. Em seguida, toda a configuração necessária foi feita em um processo em segundo plano que aplicou um estado Terraform criado dinamicamente para criar uma instância EC2 pronta para uso.
Como acontece com qualquer solução caseiraé comum encontrar bugs únicos e comportamentos inesperados que podem ser difíceis de prever. Por exemplo, houve um tempo em que o provisionamento dinâmico do Terraform resultava no provisionamento de instâncias duas vezes. Isso criou um desafio, pois essas instâncias duplicadas não eram rastreadas, usadas ou desalocadas. Isso causou um desperdício significativo de dinheiro até descobrirmos e resolvermos o problema.
A escalabilidade foi outro desafio importante que enfrentamos. Quando os usuários precisavam de mais recursos, nossa única opção para escalar verticalmente period oferecer instâncias maiores. Com a emocionante revolução do LLM, esse desafio tornou-se ainda mais urgente, já que a proteção de grandes instâncias na AWS agora poderia levar semanas! Além disso, como cada instância do EC2 estava vinculada à pessoa que a criou, isso tornou os recursos ainda mais escassos.
Além dos problemas de escalabilidade, havia outras desvantagens:
- Problemas de suporte: Essas instâncias EC2 de longa duração, personalizadas e com estado eram difíceis de suportar adequadamente e tinham menos de 25% de utilização, em média.
- Limitações técnicas: Devido aos detalhes de implementação, as instâncias estavam restritas a uma única região da AWS e a um conjunto limitado de zonas de disponibilidade, o que complicou a expansão e o acesso rápido aos tipos de instâncias EC2 mais recentes.
- Preocupações de segurança: A aplicação de patches de segurança e o alinhamento com os requisitos mais recentes foi um desafio.
Dados os desafios e o escopo do trabalho necessário para enfrentá-los no sistema legado, concluímos que period o momento certo para mudanças mais radicais.
Implementação da nova infraestrutura de ML
Assim que decidimos construir uma infraestrutura totalmente nova, sentamos para listar os requisitos básicos do sistema. Em sua essência, existem apenas três partes principais: armazenamento, recursos de computação, e acesso a outros serviços.
Recursos de computação: Uma mudança importante foi passar de instâncias EC2 personalizadas e com estado para clusters de computação alocados dinamicamente sobre recursos de computação compartilhados. Conseguimos isso migrando do EC2 para o EKS (ambiente Kubernetes), o que nos permitiu dissociar o armazenamento dos recursos de computação e passar de recursos personalizados para recursos alocados dinamicamente.
Armazenar: Embora o EFS continuasse sendo a principal opção de armazenamento em sistemas legados, passamos do armazenamento compartilhado world para o armazenamento EFS por equipe e fornecemos buckets S3 como uma opção mais adequada para determinados casos de uso.
Acesso a outros serviços: Em vez de gerenciar dezenas de hyperlinks privados entre contas diferentes, centralizamos o acesso aos endpoints no Proxy ICAP, por meio do qual todas as solicitações eram roteadas.
Um dos princípios básicos do projeto period escrever o mínimo de código possível e combinar apenas soluções de código aberto em um sistema funcional.
No ultimate, nossas escolhas técnicas podem ser resumidas assim:
- Kubernetes (K8s) — o principal padrão da indústria para abstração computacional
- Karpenter — um padrão para provisionamento dinâmico de recursos computacionais em K8s
- KubeRay—estrutura de orquestração de computação em cluster
- CD Argo—K8s GitOps e ferramenta CI/CD
- CLI/Serviço Python—um wrapper fino para permitir que os usuários interajam com o sistema e gerenciem seus clusters de computação
Vamos ver como usamos essas ferramentas.
Como tudo isso funciona junto
Usamos tecnologias de código aberto (K8s, Karpenter, Argo CD, KubeRay) para todas as implantações e orquestração. Para tornar o sistema facilmente acessível aos usuários, usamos apenas peças simples de cliente e servidor personalizadas.
A pedido do usuário, temos um serviço que confirma os valores do Helm em nosso repositório Git e pesquisa a API do Argo CD para obter o standing da implantação. Argo CD monitora as configurações e automatiza a implantação no Kubernetes. Os gráficos Helm que estão sendo implantados envolvem KubeRay (que fornece capacidade de computação em cluster), JupyterLab, VS Code e servidores SSH (que fornecem diferentes tipos de UI para os usuários interagirem) como opções de implantação, dependendo do caso de uso.
Esse fluxo nos permitiu transferir operações complexas, como provisionamento e monitoramento de standing, para ferramentas de código aberto, portanto, não precisamos de nenhum código personalizado para essas funções.
Fluxo de trabalho dos usuários
Com a nova infraestrutura, os fluxos de trabalho dos nossos utilizadores mudaram, mas também permitiu torná-los mais eficientes.
Agora, os usuários criam um cluster que gera um modelo de arquivo YAML com todos os recursos necessários para alocar, quais imagens Docker devem ser usadas e que tipo de UI ela deve fornecer.
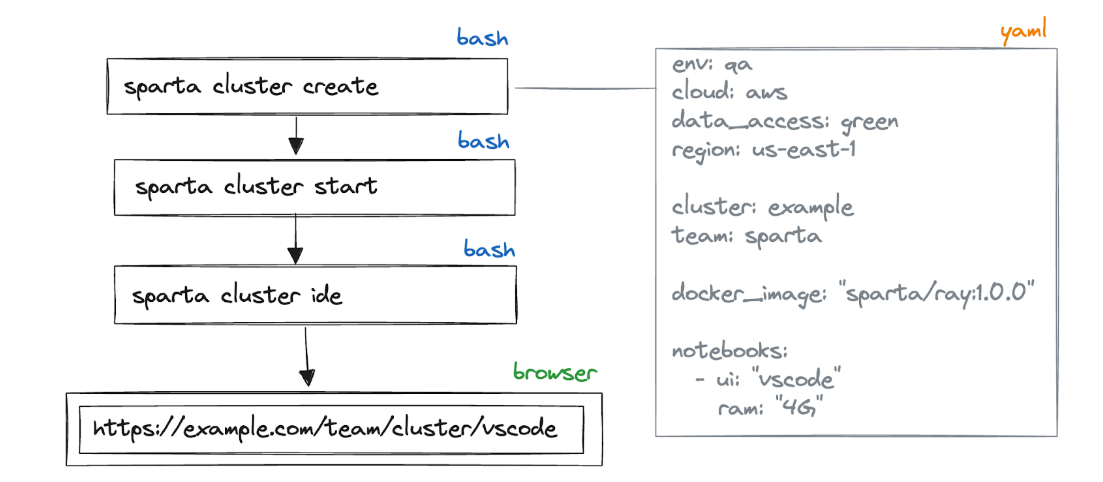
Depois disso, eles iniciam o cluster, que abre uma UI da net no navegador ou fornece uma string de conexão SSH.
Desafios de design e implementação
Ao longo do caminho, encontramos algumas opções de design interessantes que gostaríamos de descrever em detalhes.
O servidor se compromete com um repositório Git remoto
No novo sistema, a CLI envia a configuração do cluster para o serviço de backend. No entanto, a configuração deve de alguma forma ser colocada no repositório Git de configuração centralizado, onde pode ser descoberta e implantada pelo Argo CD. Nosso serviço de design envia alterações diretamente para um repositório Git remoto (GitLab em nosso caso). Chamamos isso de abordagem GitDb, pois substituímos o banco de dados por um repositório Git e enviamos alterações para ele.
Como acontece com qualquer sistema que se torne well-liked entre os usuários, precisamos aumentá-lo adicionando novas réplicas. Portanto, agora, várias réplicas do serviço podem enviar commits simultaneamente para a mesma ramificação remota do Git. Basicamente, podemos ter problemas com uma gravação clássica de banco de dados distribuído.
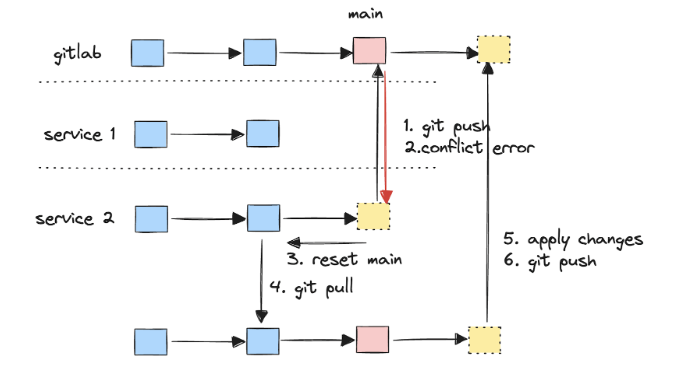
Por exemplo, se uma réplica de serviço tentar fazer push para a ramificação principal do GitLab enquanto outra réplica já tiver feito isso, ocorrerá um erro de conflito de push do Git. Portanto, é importante implementar uma lógica de reversão e nova tentativa bem testada, como a da imagem.
Eventualmente, precisávamos resolver problemas de simultaneidade cada vez mais complexos relacionados a essa decisão de design. Sugerimos simplificar ao máximo essas soluções personalizadas, recorrendo a lógicas personalizadas mais complexas apenas quando necessário.
Vários provisionadores Karpenter
O Karpenter foi usado para aumentar e diminuir nossos clusters automaticamente. Considerando as diversas necessidades da nossa equipe, criamos provisionadores especializados para cada caso de uso. Também é importante garantir que estes fornecedores não entrem em conflito entre si, pois os conflitos podem levar a decisões de agendamento abaixo do ultimate.
Existem três provisionadores configurados em nossa configuração:
- O provisionador padrão atende solicitações de recursos de CPU/RAM (ou seja, cargas de trabalho que não são de GPU).
- O provisionador de GPU gerencia os recursos de GPU, garantindo que cargas de trabalho que não sejam de GPU não sejam agendadas em instâncias de GPU caras.
- O provisionador de reserva de capacidade gerencia grandes recursos e garante que cargas menores não serão agendadas para instâncias grandes.
Forte integração com reservas de capacidade
Um de nossos principais casos de uso é o treinamento e o ajuste fino de LLMs (grandes modelos de linguagem). Temos uma demanda cada vez maior por tipos de instâncias grandes (como p4de.24xlarge, p5.48xlarge), que não estão disponíveis de forma confiável no mercado sob demanda. Portanto, usamos extensivamente as reservas de capacidade da AWS. Construímos uma integração abrangente em torno dele para visualizar claramente o uso atual das reservas e fornecer notificações sobre reservas expiradas.
Desafios de adoção
O principal desafio do projeto foi alcançando a adoção do usuário. Motivação, paridade de recursos e prazos apertados foram os principais fatores na adoção.
Abordamos isso caso a caso. Criamos uma lista de histórias de usuários para garantir que os usuários não estivessem simplesmente migrando para uma nova ferramenta, mas também ganhando funcionalidades adicionais. Isso mudou o contexto da migração para as equipes e ajudou a priorizar. Também conseguimos a aprovação da alta administração para tornar a migração uma meta de toda a empresa.
Outro desafio técnico significativo para adoção foi usando imagens Docker e abstrações Kubernetes. Os pesquisadores estão acostumados com instâncias EC2 simples e com estado, por isso precisávamos documentar e comunicar as diferenças para que os pesquisadores se sentissem confortáveis novamente. Desenvolvemos modelos e automação de CI para simplificar a criação de imagens Docker, tornando-a tão fácil quanto escrever um script bash personalizado. Posteriormente, também introduzimos scripts bash de inicialização para fornecer um ciclo de suggestions mais curto e tornar a experiência ainda mais semelhante à do sistema legado.
Benefícios e impacto
Durante a implementação do projeto, achamos útil garantir que nós mesmos e todas as partes interessadas entendíamos a necessidade do projeto e que os usuários viam valor na migração para a nossa nova solução.
Os resultados mais valiosos e mensuráveis do projeto foram:
- Os linguistas se beneficiam da redução significativa do tempo de configuração: economizamos várias horas por pessoa por dash.
- Os membros da equipe de ML esperam muito menos tempo pelos recursos, pois podem se beneficiar do uso de um pool compartilhado de recursos de instâncias grandes. Antes, eles precisavam esperar de alguns dias a 30 dias pelos recursos computacionais. Agora, o tempo está reduzido a zero, pois possibilitamos o planejamento e o compartilhamento antecipado das necessidades de recursos.
- Nossa infraestrutura ficou mais fácil de corrigir e atualizar para se alinhar aos novos requisitos, fortalecendo a segurança.
- Por último, mas não menos importante, centralizámos as nossas ferramentas em torno de uma única ferramenta entre diferentes equipas, o que permitiu a partilha de recursos e conhecimentos.
Pensamentos finais
Este projeto nos trouxe vários insights valiosos ao longo do caminho. Se recomeçassemos, com certeza daríamos mais atenção às necessidades e dores do cliente com o ferramental atual desde o início. O projeto foi estruturado para ser flexível e atender às necessidades futuras dos usuários; no entanto, uma lista mais abrangente de requisitos desde o início teria nos ajudado a poupar um esforço considerável no ajuste. Também evitaríamos repetir os mesmos erros cometidos no sistema legado, como aumentar a complexidade da base de código customizada que suporta a infraestrutura. Além disso, procuraríamos proativamente soluções prontas para uso para substituir componentes personalizados.
Nossa conclusão no momento é que substituir completamente nossa pilha de ML por uma solução SaaS não atenderia exatamente às nossas necessidades e reduziria a produtividade. Ter whole controle e um profundo conhecimento de todo o sistema nos coloca em uma posição forte junto aos nossos usuários internos, que escolheram esta solução em detrimento de outras alternativas. Além disso, ter componentes extensíveis e substituíveis torna a configuração mais flexível. Isso contrasta com soluções completas prontas para uso, como KubeFlow ou Databricks. Dito isto, avaliamos constantemente as nossas ferramentas e ajustamo-las à indústria; estamos abertos para revisitar isso no futuro.
Se você deseja trabalhar na fronteira do ML e da IA e ajudar o mundo a se comunicar melhor ao longo do caminho, confira nossas vagas de emprego aqui.





